5 月 20 日消息,科技媒體 marktechpost 昨日(5 月 19 日)發布博文,報道稱谷歌 DeepMind 團隊聯合約翰?開普勒林茨大學 LIT AI 實驗室,通過強化學習微調(RLFT)技術,提升語言模型的決策能力。
IT之家援引博文介紹,基于海量互聯網數據訓練的語言模型已展現出超越文本處理的決策潛力,可以通過內部知識推理,在交互環境中做出行動選擇。
不過這些語言模型在決策過程存在顯著缺陷:模型能推導正確策略卻無法執行(knowing-doing gap,紙上談兵),過度偏好短期高回報選項(greediness,貪婪選擇),較小模型還會機械重復常見動作(frequency bias,頻次偏見)。
傳統強化學習方法如 UCB 算法雖能平衡探索與利用,但難以解決模型內在的推理-行動脫節問題。
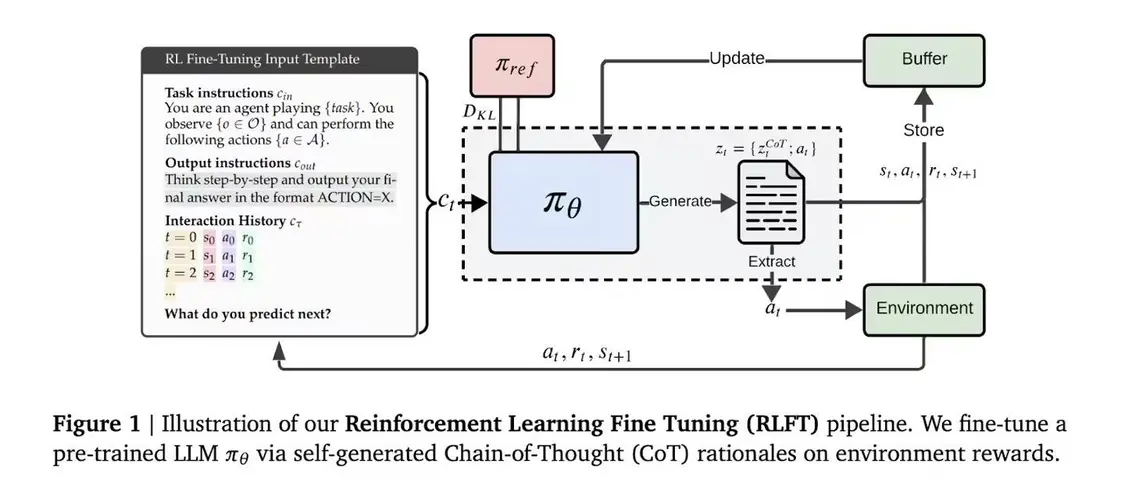
DeepMind 團隊創新采用強化學習微調技術,以模型自生成的思維鏈作為訓練信號,系統會評估每個推理步驟對應的行動獎勵,促使模型優先選擇邏輯自洽且實際高效的行動方案。
具體實施時,模型根據輸入指令和行動-獎勵歷史生成包含推理過程與動作的序列,通過蒙特卡洛(Monte Carlo)基線評估和廣義優勢估計進行優化;無效動作會觸發懲罰機制,而獎勵塑造技術既保證輸出格式規范,又保留探索空間。
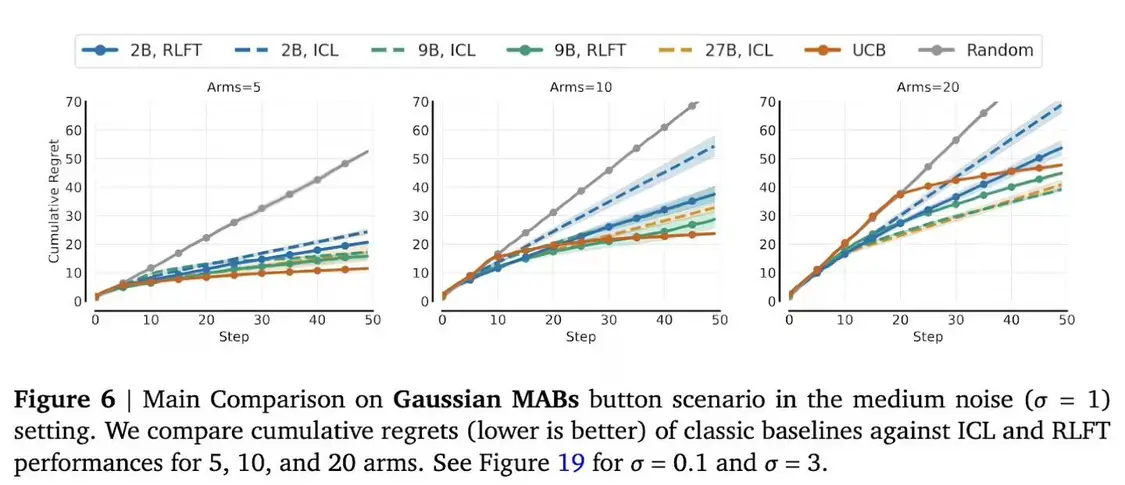
在 10 臂的多臂老虎機(multi-armed bandit,MAB,有擁有 N 根拉桿的老虎機,拉動每一根拉桿都對應一個關于獎勵的概率分布)測試中,2B 參數模型的動作覆蓋率提升 12 個百分點;面對 20 臂時改善幅度雖小但仍有意義,其頻次偏見率從 70% 驟降至 35%。
井字棋實驗中,模型對陣隨機對手的勝率提升 5 倍,與最優蒙特卡洛樹搜索代理的對戰平均回報從-0.95 歸零。值得注意的是,27B 大模型生成正確推理的概率達 87%,但未微調時僅 21% 會執行最優動作,該強化學習微調有效縮小了這一差距。
【來源:IT之家】




















